반응형
특정페이지를 가져올 때 간단하게 사용한다. 파이썬으로 주로 크롤링을 개발하지만 생각보다 자바로도 크롤링을 구현하는게 어렵지않다. 크롬드라이버를 써서 구현할 수도 있다. 자바의 장점은 쓰레드 구현이 쉬워서 다중으로 처리할 경우 의외로 편하다.
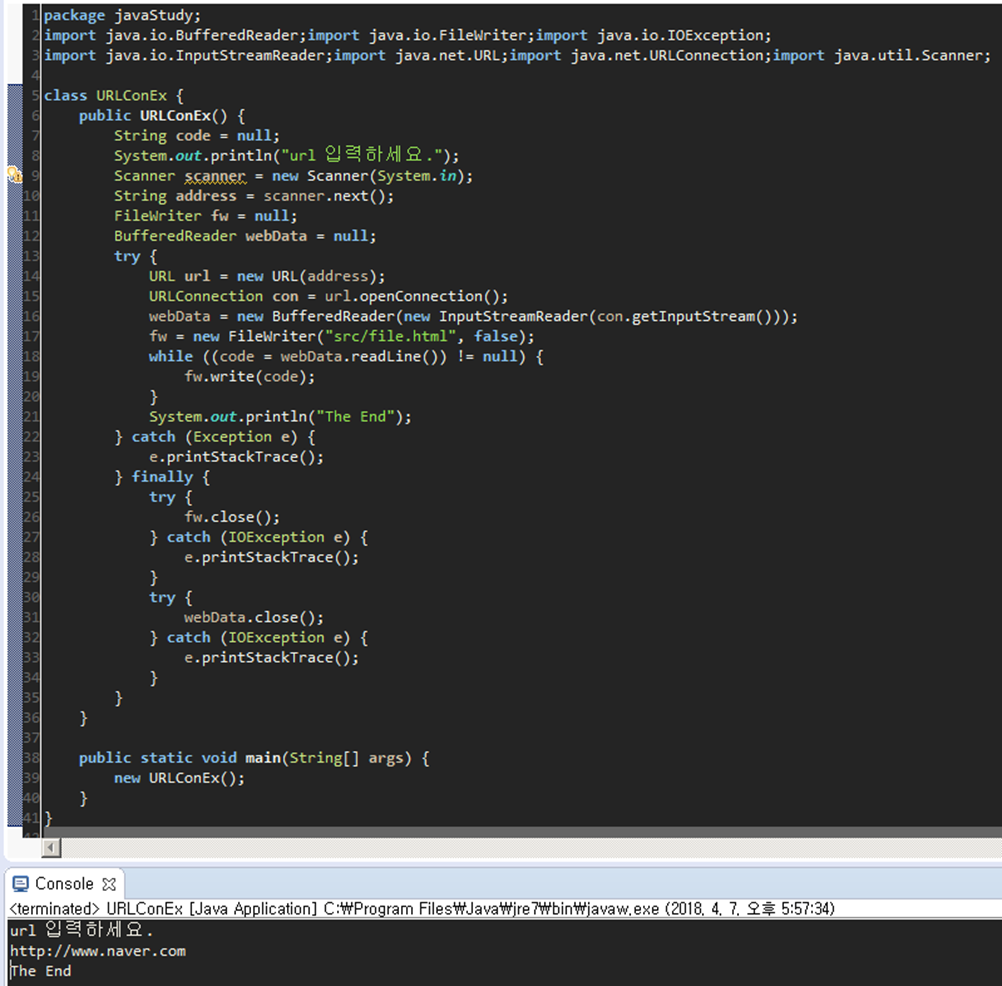
package javaStudy;
import java.io.BufferedReader;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URL;
import java.net.URLConnection;
import java.util.Scanner;
class URLConEx {
public URLConEx() {
String code = null;
System.out.println("url 입력하세요.");
Scanner scanner = new Scanner(System.in);
String address = scanner.next();
FileWriter fw = null;
BufferedReader webData = null;
try {
URL url = new URL(address);
URLConnection con = url.openConnection();
webData = new BufferedReader(new InputStreamReader(con.getInputStream()));
fw = new FileWriter("src/file.html", false);
while ((code = webData.readLine()) != null) {
fw.write(code);
}
System.out.println("The End");
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
fw.close();
} catch (IOException e) {
e.printStackTrace();
}
try {
webData.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
new URLConEx();
}
}열린 io리소스는 닫아야 한다.
일반적으로 IO처리 부분은 Reader, Writer, Stream등에 집중하여 코드를 검토한다.
URL url = new URL(address); url주소를 받아서
URLConnection con = url.openConnection(); 페이지에 접속을 하고
webData = new BufferedReader(new InputStreamReader(con.getInputStream())); 스트림을 읽어서 버퍼에 적재
반응형
'JAVA' 카테고리의 다른 글
| 자바 hashmap (0) | 2023.01.24 |
|---|---|
| 자바 파일입출력 (0) | 2023.01.24 |
| 자바 쓰레드 (0) | 2023.01.24 |
| 자바 JDBC (0) | 2023.01.24 |
| JAVA JSONObject (0) | 2023.01.23 |

댓글